٢ دقائق للقراءة
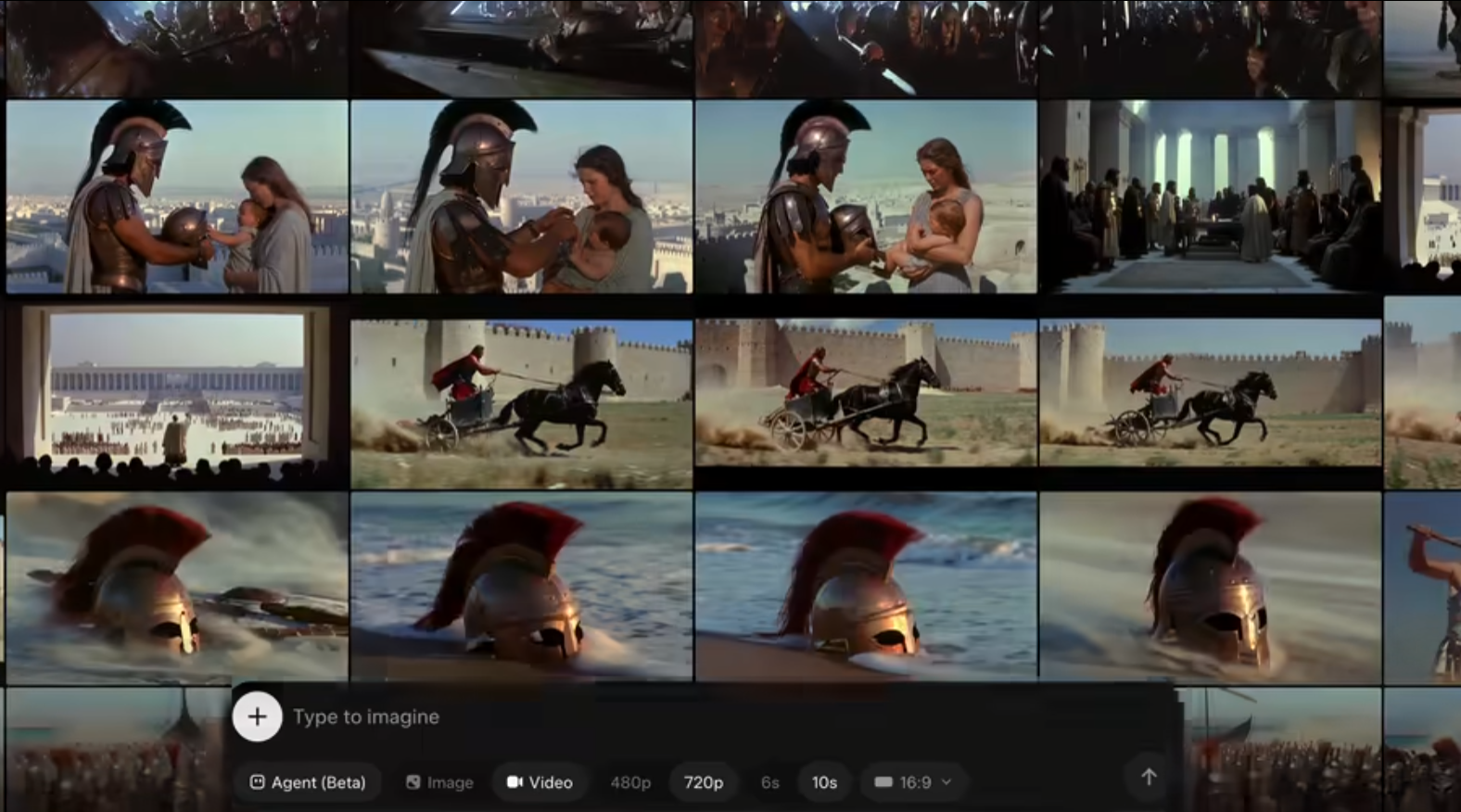
إطلاق xAI نموذج Grok Imagine 1.5 لتحويل الصور إلى فيديوهات
تابع هذه المواضيع
سجّل دخولك لمتابعة المواضيع التي تهمك
رأي الذكاء الاصطناعي
يمثل نموذج Grok Imagine 1.5 تحولاً جذرياً في كيفية إنتاج المحتوى المرئي، مما يفتح آفاقاً جديدة للمبدعين. يمكن أن يعزز هذا الابتكار من قدرة الشركات على جذب الجمهور من خلال محتوى مرئي أكثر تفاعلية.
الرأي المقابل
ومع ذلك، قد يواجه هذا النموذج تحديات تتعلق بالجودة والدقة، حيث أن تحويل الصور إلى فيديوهات قد لا يحقق دائماً النتائج المرجوة. كما أن الاعتماد على الذكاء الاصطناعي في الإنتاج قد يقلل من اللمسة البشرية في الفن.
يُنتج هذا الملخص باستخدام تقنيات الذكاء الاصطناعي مع مراجعة تحريرية دورية، ويرجى الرجوع إلى المصدر الأصلي للتفاصيل الكاملة.
إطلاق xAI نموذج Grok Imagine 1.5 لتحويل الصور إلى فيديوهات
تابع هذه المواضيع
سجّل دخولك لمتابعة المواضيع التي تهمك
رأي الذكاء الاصطناعي
يمثل نموذج Grok Imagine 1.5 تحولاً جذرياً في كيفية إنتاج المحتوى المرئي، مما يفتح آفاقاً جديدة للمبدعين. يمكن أن يعزز هذا الابتكار من قدرة الشركات على جذب الجمهور من خلال محتوى مرئي أكثر تفاعلية.
الرأي المقابل
ومع ذلك، قد يواجه هذا النموذج تحديات تتعلق بالجودة والدقة، حيث أن تحويل الصور إلى فيديوهات قد لا يحقق دائماً النتائج المرجوة. كما أن الاعتماد على الذكاء الاصطناعي في الإنتاج قد يقلل من اللمسة البشرية في الفن.
يُنتج هذا الملخص باستخدام تقنيات الذكاء الاصطناعي مع مراجعة تحريرية دورية، ويرجى الرجوع إلى المصدر الأصلي للتفاصيل الكاملة.
تقييم الخبر
سيظهر متوسط التقييم بعد 3 تقييمات.
لم تقم بالتقييم بعد.
0/1000
جاري تحميل التفاعلات...




