مقال
كيف النماذج تتعلم من بيانات اصطناعية؟
الشركات اللي تدرب نماذج الذكاء الاصطناعي واجهت مشكلة: البيانات البشرية عالية الجودة بدت تنفد. البيانات الاصطناعية صارت الحل العملي، لكنها تحتاج آليات صارمة للتحكم بالجودة علشان ما تدخل في دورة من التدهور التدريجي.

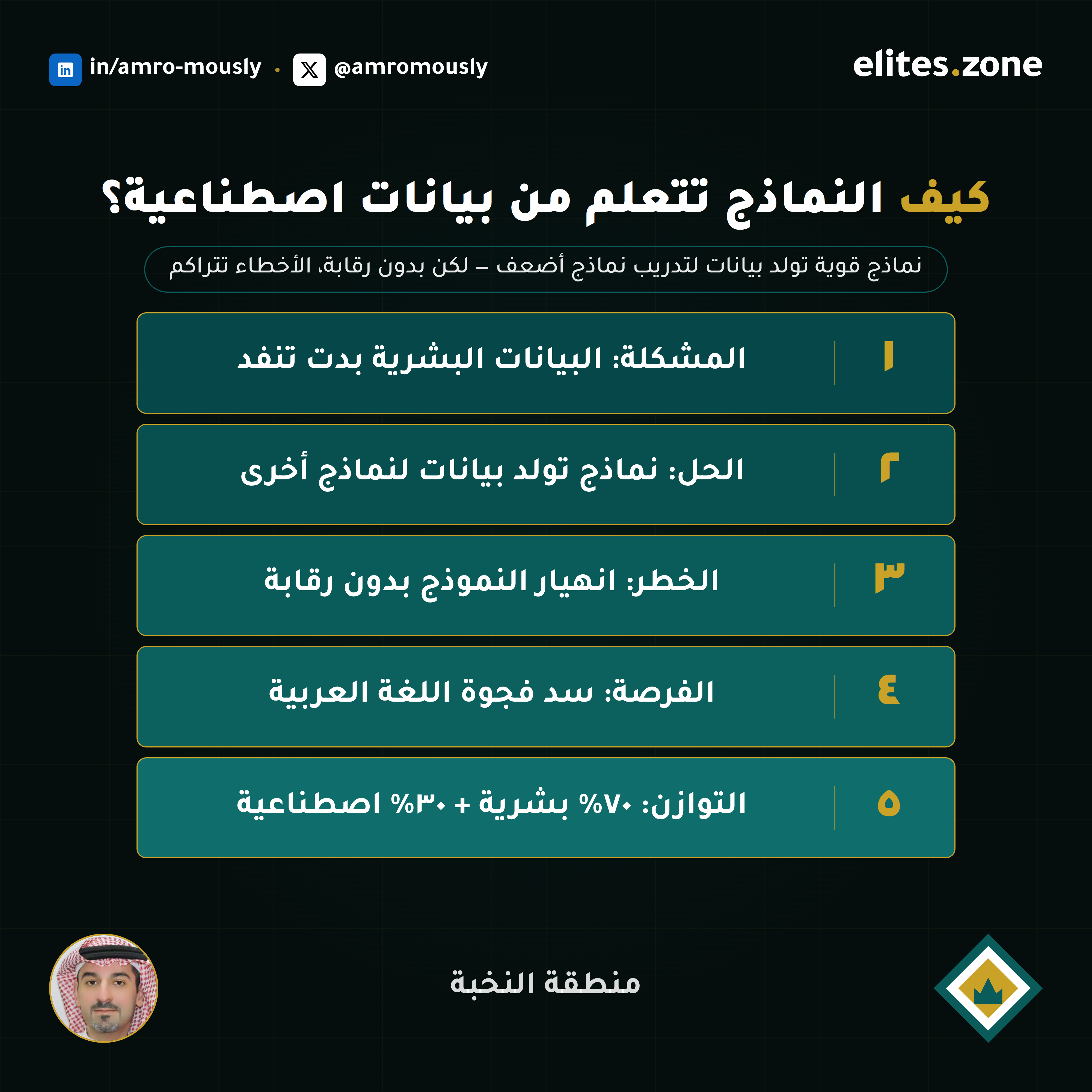
الشركات اللي تدرب نماذج الذكاء الاصطناعي واجهت مشكلة ما كانوا يتوقعوها: البيانات البشرية عالية الجودة بدت تنفد. المحتوى اللي على الإنترنت اللي كان يكفي لتدريب أجيال سابقة من النماذج، صار محدود جدًا مقارنة بحجم النماذج الجديدة اللي تحتاج تريليونات من الكلمات علشان تتعلم. هنا ظهر الحل اللي يبدو غريب: نماذج ذكاء اصطناعي تولد بيانات لتدريب نماذج ذكاء اصطناعي أخرى.
البيانات الاصطناعية — Synthetic Data صارت الحل العملي لمشكلة الندرة هذي. الفكرة بسيطة: تستخدم نموذج قوي ومتقدم علشان يولد محتوى تدريبي لنموذج أضعف أو متخصص. مثلًا، نموذج زي GPT-4 يقدر يولد آلاف الأمثلة لحالات استخدام معينة، حوارات، أو حتى أكواد برمجية، وهذي البيانات تستخدم لتدريب نماذج أصغر أو متخصصة في مجالات ضيقة. الطريقة هذي ما توفر الوقت والتكلفة بس، لكن تفتح المجال لتدريب نماذج في لغات ومجالات ما فيها بيانات بشرية كافية.
لكن الموضوع مو بسيط زي ما يبدو. البيانات الاصطناعية تحتاج آليات صارمة للتحكم بالجودة. الشركات اللي تستخدمها تطبق أنظمة تصفية معقدة: التحقق من المنطق، مراجعة بشرية لعينات، ومقارنة المخرجات بمعايير محددة. بدون الرقابة هذي، البيانات المولدة ممكن تحمل أخطاء أو تحيزات من النموذج الأصلي، وتنتقل للنموذج الجديد وتتضخم مع الوقت. الخطر الحقيقي هنا اسمه انهيار النموذج — Model Collapse: لما النماذج تتدرب على بيانات مولدة من نماذج سابقة، الأداء يتدهور جيل بعد جيل، لأن الأخطاء الصغيرة تتراكم وتصير أكبر.
بالنسبة لصناع القرار في الشركات، البيانات الاصطناعية تفتح فرص استراتيجية واضحة. لو شركتك تشتغل في مجال متخصص — زي الطب، القانون، أو الخدمات المالية — وما عندك بيانات تدريبية كافية، البيانات الاصطناعية تقدر تسد الفجوة. بدل ما تنتظر سنوات علشان تجمع بيانات حقيقية، تقدر تولد سيناريوهات واقعية وتدرب نموذجك عليها بسرعة. لكن السؤال اللي لازم تسأله: هل عندك القدرة على التحقق من جودة البيانات المولدة؟ لأن بدون فريق يراجع ويصفي، راح تدرب نموذجك على ضوضاء.
السوق السعودي والخليجي عنده حالة استخدام قوية للبيانات الاصطناعية: اللغة العربية. المحتوى العربي عالي الجودة على الإنترنت أقل بكثير من الإنجليزي، والشركات اللي تبغى تبني نماذج عربية متقدمة تواجه مشكلة نقص البيانات من البداية. شركات عالمية ومحلية بدت تستخدم نماذج قوية لتوليد محتوى عربي — حوارات، مقالات، استفسارات عملاء — علشان تدرب نماذج متخصصة للسوق المحلي. هذا يعني إن الشركات اللي تستثمر في بناء أنظمة توليد وتصفية بيانات عربية اصطناعية، راح تكون عندها ميزة تنافسية واضحة.
لكن الاعتماد الكامل على البيانات الاصطناعية فيه مخاطر. لو كل شركة بدت تدرب نماذجها على بيانات مولدة من نماذج أخرى، راح ندخل في دورة من التدهور التدريجي. علشان كذا، الشركات الذكية تستخدم البيانات الاصطناعية كمكمل مو بديل. تخلطها مع بيانات بشرية حقيقية، وتحط نسب واضحة: مثلًا 70% بيانات بشرية و30% اصطناعية. وتراقب الأداء باستمرار علشان تتأكد إن الجودة ما تتراجع.
الخلاصة العملية: البيانات الاصطناعية مو حل سحري، لكنها أداة قوية لو استخدمتها صح. لو شركتك تخطط لبناء أو تخصيص نموذج ذكاء اصطناعي، اسأل نفسك: هل عندنا بيانات بشرية كافية؟ لو الجواب لا، البيانات الاصطناعية ممكن تسرع المشروع. لكن لازم تبني نظام رقابة وتصفية قوي، وتحافظ على نسبة من البيانات البشرية في كل دورة تدريب. الشركات اللي تفهم التوازن هذا، راح تبني نماذج أقوى وأسرع من المنافسين.
---
تقييم المقال
سيظهر متوسط التقييم بعد 3 تقييمات.
لا توجد تعليقات بعد. كن أول من يعلق!